Painel de líderes




Conteúdo popular
Showing content with the highest reputation on 14-01-2026 em todas as áreas
-
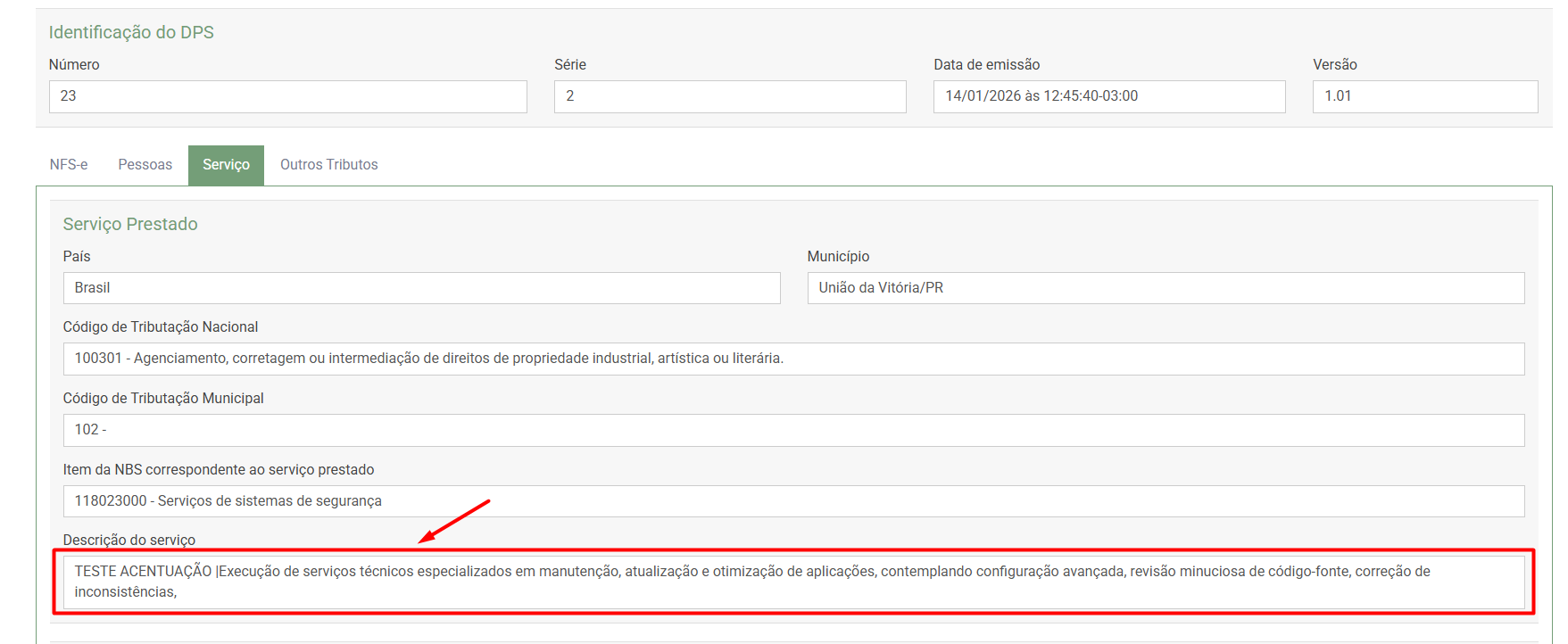
Descrição do problema Foi identificado um problema recorrente na transmissão e recuperação de XML (e conteúdos textuais retornados, inclusive estruturas convertidas para XLS/relatórios) no NFSeX – Provedor Nacional, onde ocorre erro de acentuação e corrupção de caracteres. <infNFSe Id="NFS41282032204580454000130000000000002626012373413140"> <xLocEmi>Uni?o da Vit?ria</xLocEmi> <xLocPrestacao>Uni?o da Vit?ria</xLocPrestacao> <nNFSe>26</nNFSe> <infNFSe Id="NFS41282032204580454000130000000000002626012373413140"> <xLocEmi>Uni?o da Vit?ria</xLocEmi> <xLocPrestacao>Uni?o da Vit?ria</xLocPrestacao> <nNFSe>26</nNFSe> <xTribNac> Lubrifica??o, limpeza, lustra??o, revis?o, carga e recarga, conserto, restaura??o, blindagem, manuten??o e conserva??o de m?quinas, ve?culos, aparelhos, equipamentos, motores, elevadores ou de qualquer objeto (exceto pe?as e partes empregadas, que ficam sujeitas ao ICMS). </xTribNac> <xNBS>Servi?os de sistemas de seguran?a</xNBS> <verAplic>SefinNacional_1.5.0</verAplic> <ambGer>2</ambGer> <tpEmis>1</tpEmis> <procEmi>1</procEmi> <cStat>100</cStat> <dhProc>2026-01-12T19:56:19-03:00</dhProc> <nDFSe>53116</nDFSe> <emit> A causa principal está no fato de que, em diversos pontos do código do ACBr, existem conversões implícitas de tipos (string, AnsiString e UTF-8). Esse comportamento não gera erro aparente no Lazarus/FPC, pois nesse ambiente o tipo string já é UTF-8 por padrão. Entretanto, no Delphi 2009+ (Unicode), essas conversões implícitas passam a ser críticas, resultando em: UTF-8 interpretado como ANSI Dupla conversão de encoding Mojibake (acentuação quebrada) Perda de caracteres tanto no envio quanto no retorno do processamento Observação importante Esse problema já foi reportado diversas vezes pela comunidade. Historicamente, a solução sugerida tem sido habilitar a opção de “remover acentos” nos textos enviados. No entanto, essa não é uma solução correta. A acentuação em UTF-8 é plenamente aceita, não possui qualquer restrição no layout e é inclusive utilizada internamente pelo servidor da NFSe Nacional. Remover acentos apenas mascara o problema, elimina informação válida do texto e não resolve a causa real, que é o tratamento incorreto de charset no código. Portanto, o problema precisa ser resolvido na origem, com a correção adequada dos fontes e do fluxo de encoding. Esse cenário afeta diretamente: Envio do XML da NFSe Retorno das mensagens do webservice Textos livres (descrições, observações, mensagens de erro) Conteúdos recuperados e posteriormente exportados/visualizados (ex.: XML → XLS) Diante disso, tornou-se necessária a correção dos fontes, eliminando conversões implícitas e garantindo tratamento explícito de UTF-8. Adequação realizada Foi realizada uma adequação no código da NFSe – Padrão Nacional, com foco em Delphi 2009+, corrigindo problemas de acentuação e encoding decorrentes do uso incorreto de AnsiString em fluxos que exigem UTF8String. A correção é indispensável porque o servidor da NFSe Nacional exige que todo o conteúdo enviado esteja obrigatoriamente em UTF-8, incluindo: XML principal Mensagens de troca com o webservice Textos livres (descrições, observações, mensagens de erro, etc.) Antes do ajuste, parte do código realizava conversões implícitas ou indevidas entre string, AnsiString e UTF-8, ocasionando mojibake (conteúdo UTF-8 interpretado como ANSI), com impacto direto na acentuação tanto no envio quanto no retorno do processamento. O que foi corrigido Padronização do tratamento de dados textuais enviados ao webservice como UTF8String Eliminação de conversões implícitas que causavam dupla interpretação de encoding Correção de pontos críticos de: Compressão e descompressão Gravação e leitura de arquivos Manipulação de XML Comunicação HTTP Garantia de retorno correto dos caracteres acentuados após o processamento Correção dos dados recuperados, evitando erros de acentuação em exportações e visualizações (ex.: XML/XLS) Compatibilidade A solução mantém total compatibilidade com: Lazarus / FPC (onde string já é UTF-8) Delphi antigo (pré-Unicode) Delphi Unicode (2009+) Foram utilizadas diretivas de compilação para assegurar o comportamento correto em cada ambiente, sem impacto regressivo. Arquivos alterados Os seguintes arquivos foram modificados para aplicar a correção de encoding e eliminar problemas de mojibake: ACBrXmlDocument.pas PadraoNacional.Provider.pas ACBrNFSeXWebserviceBase.pas ACBrDFeXsLibXml2.pas ACBrDFe.pas ACBrUtil.XMLHTML.pas ACBrUtil.Strings.pas ACBrUtil.FilesIO.pas ACBrCompress.pas Estou disponibilizando os arquivos corrigidos, juntamente com o resultado do processamento após a correção, para validação técnica e compartilhamento com a comunidade. exemplo do funcionamento da correção Logs.7z
 1 ponto
1 ponto -
Pedido à comunidade Esse problema de acentuação / charset UTF-8 no NFSeX – Provedor Nacional já foi relatado diversas vezes e afeta principalmente ambientes Delphi 2009+. Peço, por gentileza, que os usuários que enfrentam o mesmo erro: Testem as alterações propostas Confirmem a correção do envio e do retorno da NFSe com acentuação UTF-8 correta Marquem aqui nos comentários caso também tenham esse problema A participação de vocês ajuda a demonstrar que o erro é recorrente e reforça a necessidade de commit da correção nos fontes, eliminando definitivamente paliativos como a opção de “remover acentos”. Obrigado a todos pela colaboração.1 ponto
-
Oi, eu não precisei fazer as alterações, validei com as units do Wesley e ja funcionou aqui.1 ponto
-
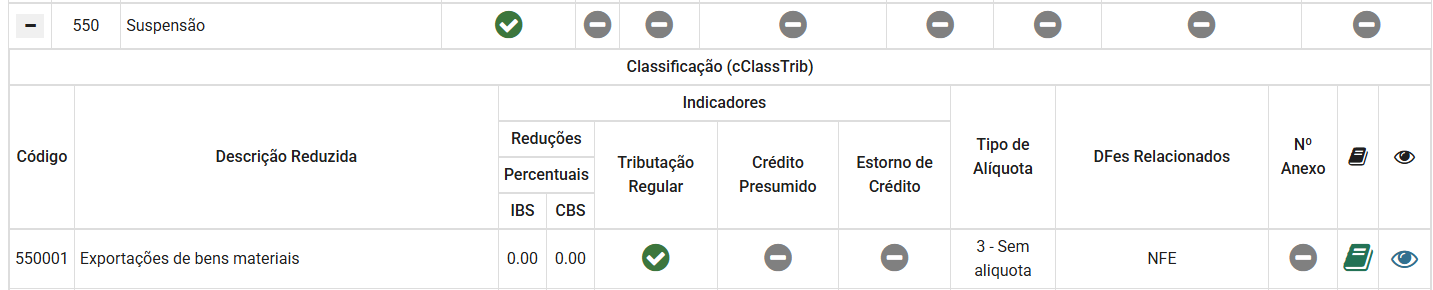
https://dfe-portal.svrs.rs.gov.br/DFE/ClassificacaoTributaria Vc deve informar o grupo Tributação Regular.
1 ponto
-
@Juliomar Marchetti Era esse campo mesmo, eu não tinha me atendando para ver que a classe herdava do padrão nacional.1 ponto
-
1 ponto
-
Ola julimar, comentei estas 2 linhas: // LoadXML(XmlEnvio, WBXmlEnvio, 'temp1.xml'); //LoadXML(XmlRetorno, WBXmlRetorno, 'temp2.xml'); E ai o erro apareceu, esquisito que o ERRO tinha que vim antes ne..... O erro era que no FONE: Tinha caracteres TRACO (-) 43-9999-9999, por isso q dava o erro... Mas deu certo, e agora esta gerando ate em produção... Muito Obrigado pela Atenção Topico fechado!!1 ponto
-
sempre lembre-se que tem os fontes estão é só procurar . senão me engano está com padrão nacional
1 ponto
-
Para o CST 00 não vai gerar as tags de ICMS-ST.1 ponto
-
Realizei os testes em Sapezal-MT, e consegui emitir e consultar. Já nos municípios Barracão-PR e Campos Novos-SC, tive os mesmos erros mencionados anteriormente. Obrigado @Alex Heinen e @Francisco IBS, pelas informaçoes fornecidas.1 ponto
-
Ok, vc esta certo, eu validei um envio com essas alteracoes da pasta que vc mencionou e o envio aconteceu com sucesso. Inclusive para o ambiente nacional, gerando Chave de acesso. A consulta tbm funcionou e trouxe os dados para atualizacao no meu erp. Porém, não consegui cancelar. Vc esta conseguindo? Tentei enviar conforme a documentação da betha passando o tipoIntegracao>CANCELAMENTO</e:tipoIntegracao , porem retorna "Não há nenhuma DPS com os dados utilizados"1 ponto
-
anexa as units alteradas para que possa ser validada1 ponto
-
Esta liberado sim. O problema é que o o cTribMun agora sao 2 codigos. Um Tributo nacional e outro municipal, estava colocando somente um. Ele nao sente falta do codigo, so diz que nao foi encontrado. Fica assim: <serv> <locPrest> <cLocPrestacao>3304557</cLocPrestacao> </locPrest> <cServ> <cTribNac>060401</cTribNac> <cTribMun>011</cTribMun> <xDescServ>Pagamento de : BRUNO - Referente a : MENSALIDADE</xDescServ> </cServ> </serv> Espero que ajude1 ponto
-
Retificando eu disse, deu certo, está procurando em outro fórum. Mas esse aqui tem a solução para o problema acima. Muito Obrigado att1 ponto