Painel de líderes



![[Bruno]](https://www.projetoacbr.com.br/forum/uploads/monthly_2024_07/images.thumb.jpg.368870a60017937ebb01fdd2fec26224.jpg)
Conteúdo popular
Showing content with the highest reputation on 15-01-2026 em todas as áreas
-
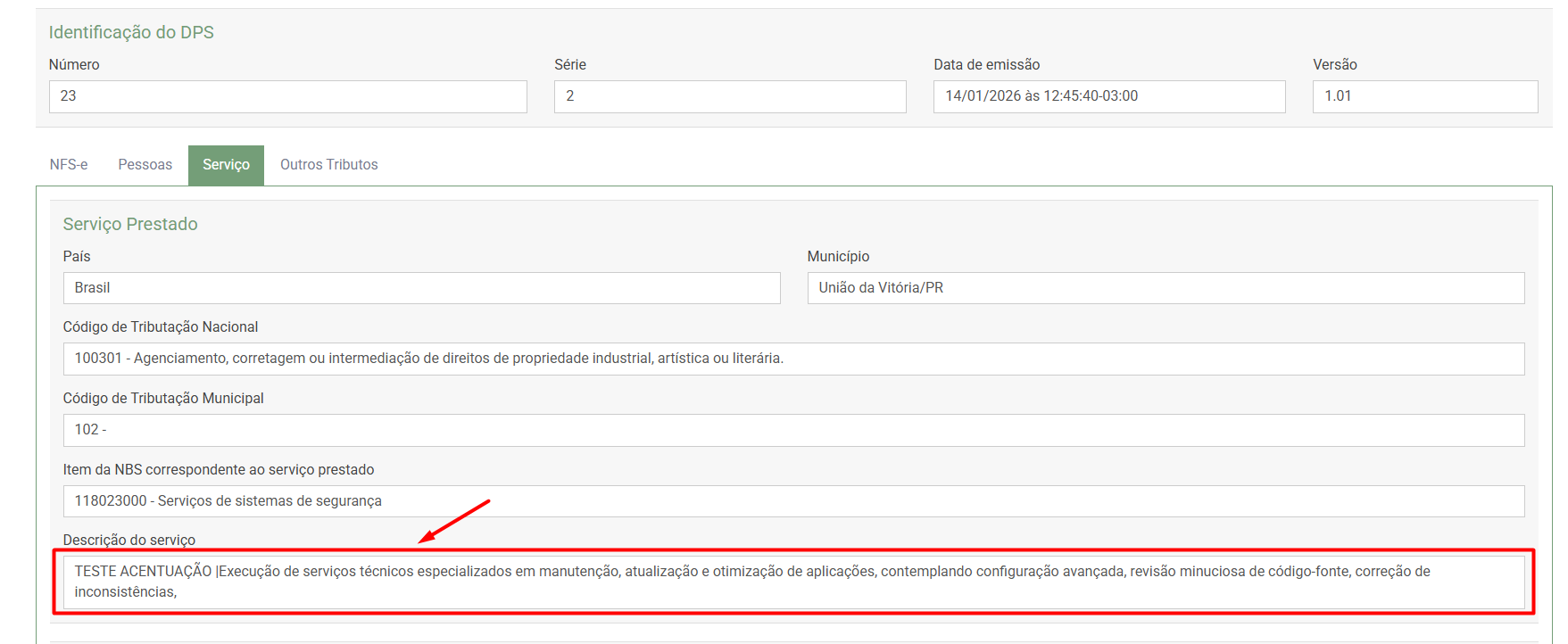
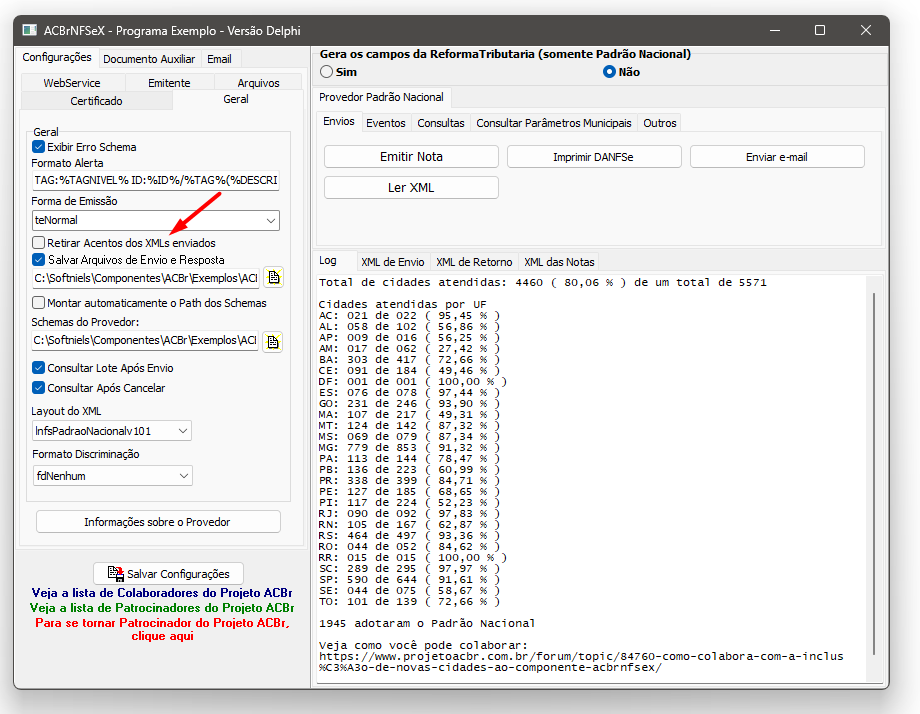
Descrição do problema Foi identificado um problema recorrente na transmissão e recuperação de XML (e conteúdos textuais retornados, inclusive estruturas convertidas para XLS/relatórios) no NFSeX – Provedor Nacional, onde ocorre erro de acentuação e corrupção de caracteres. <infNFSe Id="NFS41282032204580454000130000000000002626012373413140"> <xLocEmi>Uni?o da Vit?ria</xLocEmi> <xLocPrestacao>Uni?o da Vit?ria</xLocPrestacao> <nNFSe>26</nNFSe> <infNFSe Id="NFS41282032204580454000130000000000002626012373413140"> <xLocEmi>Uni?o da Vit?ria</xLocEmi> <xLocPrestacao>Uni?o da Vit?ria</xLocPrestacao> <nNFSe>26</nNFSe> <xTribNac> Lubrifica??o, limpeza, lustra??o, revis?o, carga e recarga, conserto, restaura??o, blindagem, manuten??o e conserva??o de m?quinas, ve?culos, aparelhos, equipamentos, motores, elevadores ou de qualquer objeto (exceto pe?as e partes empregadas, que ficam sujeitas ao ICMS). </xTribNac> <xNBS>Servi?os de sistemas de seguran?a</xNBS> <verAplic>SefinNacional_1.5.0</verAplic> <ambGer>2</ambGer> <tpEmis>1</tpEmis> <procEmi>1</procEmi> <cStat>100</cStat> <dhProc>2026-01-12T19:56:19-03:00</dhProc> <nDFSe>53116</nDFSe> <emit> A causa principal está no fato de que, em diversos pontos do código do ACBr, existem conversões implícitas de tipos (string, AnsiString e UTF-8). Esse comportamento não gera erro aparente no Lazarus/FPC, pois nesse ambiente o tipo string já é UTF-8 por padrão. Entretanto, no Delphi 2009+ (Unicode), essas conversões implícitas passam a ser críticas, resultando em: UTF-8 interpretado como ANSI Dupla conversão de encoding Mojibake (acentuação quebrada) Perda de caracteres tanto no envio quanto no retorno do processamento Observação importante Esse problema já foi reportado diversas vezes pela comunidade. Historicamente, a solução sugerida tem sido habilitar a opção de “remover acentos” nos textos enviados. No entanto, essa não é uma solução correta. A acentuação em UTF-8 é plenamente aceita, não possui qualquer restrição no layout e é inclusive utilizada internamente pelo servidor da NFSe Nacional. Remover acentos apenas mascara o problema, elimina informação válida do texto e não resolve a causa real, que é o tratamento incorreto de charset no código. Portanto, o problema precisa ser resolvido na origem, com a correção adequada dos fontes e do fluxo de encoding. Esse cenário afeta diretamente: Envio do XML da NFSe Retorno das mensagens do webservice Textos livres (descrições, observações, mensagens de erro) Conteúdos recuperados e posteriormente exportados/visualizados (ex.: XML → XLS) Diante disso, tornou-se necessária a correção dos fontes, eliminando conversões implícitas e garantindo tratamento explícito de UTF-8. Adequação realizada Foi realizada uma adequação no código da NFSe – Padrão Nacional, com foco em Delphi 2009+, corrigindo problemas de acentuação e encoding decorrentes do uso incorreto de AnsiString em fluxos que exigem UTF8String. A correção é indispensável porque o servidor da NFSe Nacional exige que todo o conteúdo enviado esteja obrigatoriamente em UTF-8, incluindo: XML principal Mensagens de troca com o webservice Textos livres (descrições, observações, mensagens de erro, etc.) Antes do ajuste, parte do código realizava conversões implícitas ou indevidas entre string, AnsiString e UTF-8, ocasionando mojibake (conteúdo UTF-8 interpretado como ANSI), com impacto direto na acentuação tanto no envio quanto no retorno do processamento. O que foi corrigido Padronização do tratamento de dados textuais enviados ao webservice como UTF8String Eliminação de conversões implícitas que causavam dupla interpretação de encoding Correção de pontos críticos de: Compressão e descompressão Gravação e leitura de arquivos Manipulação de XML Comunicação HTTP Garantia de retorno correto dos caracteres acentuados após o processamento Correção dos dados recuperados, evitando erros de acentuação em exportações e visualizações (ex.: XML/XLS) Compatibilidade A solução mantém total compatibilidade com: Lazarus / FPC (onde string já é UTF-8) Delphi antigo (pré-Unicode) Delphi Unicode (2009+) Foram utilizadas diretivas de compilação para assegurar o comportamento correto em cada ambiente, sem impacto regressivo. Arquivos alterados Os seguintes arquivos foram modificados para aplicar a correção de encoding e eliminar problemas de mojibake: ACBrXmlDocument.pas PadraoNacional.Provider.pas ACBrNFSeXWebserviceBase.pas ACBrDFeXsLibXml2.pas ACBrDFe.pas ACBrUtil.XMLHTML.pas ACBrUtil.Strings.pas ACBrUtil.FilesIO.pas ACBrCompress.pas Estou disponibilizando os arquivos corrigidos, juntamente com o resultado do processamento após a correção, para validação técnica e compartilhamento com a comunidade. exemplo do funcionamento da correção Logs.7z
 1 ponto
1 ponto -
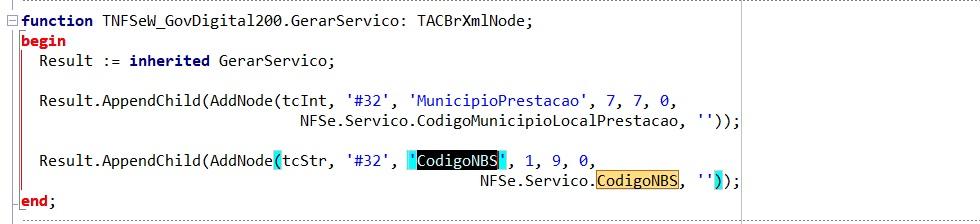
Olá pessoal Fiz alguns ajustes para atendimento ao provedor GovDigital v2.01 e foi necessario criar algumas novas propriedades na classe Servico para atender ao novo layout Servico.Valores.CSTPis Servico.Valores.tpRetPisCofins Sei que existe dentro da classe Valores a classe tribFed, mas o campo CST e do tipo TCST enquanto o layout espera um TCstPis. Seguem as units modificadas para apreciação. Acredito que mais mudanças ainda serão necessárias GovDigital.GravarXml.pas ACBrNFSeXClass.pas schema_xml_nfse_v2-01_nacional.zip AnexoVIII-CorrelacaoItemNBSIndOpCClassTrib_IBSCBS_V1.00.00.xlsx1 ponto
-
Boa tarde Boa atitude, esse Betha tá difícil1 ponto
-
é que webservice é uma coisa e o sistema web deles é outra1 ponto
-
Boa tarde. Na verdade foi encaminhado por um cliente aqui da empresa uma documentação onde foi verificado que houve mudança no layout da PriMax. Como o layout anterior deles era igual ao da WebFisco, estou na dúvida se a alteração ocorreu somente com a PriMax ou se foi no WebFisco. Procurei no fórum e não encontrei nenhum relato de problemas com o WebFisco, então acredito que a alteração vai ser somente na PriMax. Para poder atender ao nosso cliente, fiz ajustes na unit da Primax apenas, e estou na fase de testes. Tentei contato com o suporte deles porém até o momento não obtive resposta. Assim que conseguir finalizar a transmissão de uma NFSe para eles sem erros, vou disponibilizar as alterações que fiz aqui pra ajudar.1 ponto
-
Vou testar aqui o cancelamento e ver se consigo ajustar.1 ponto
-
Não tinha visto que os Schemas estão no primeiro POST Atenciosamente1 ponto
-
Olá! Funcionou assim, consegui emitir. Obrigada pela dica.1 ponto
-
https://www.projetoacbr.com.br/forum/topic/89387-acbr-8790-nfsex-–-provedor-nacional-correção-de-acentuação-e-charset-utf-8-mojibake-no-delphi-2009-com-compatibilidade-lazarus/1 ponto
-
@@C4Dev Obrigado pelo XML. O Acbr não foi ajustado para gerar as tags CIndOP e CClassTribReg por isso esta dando erro aqui ao enviar. @Italo Giurizzato Junior consegue analisar as alterações do nosso amigo @Ederson Selvati para o GovDigital ? Dercide Alvarez
1 ponto
-
já resolvi o erro obrigado1 ponto
-
Enviei no privado @Dercide Alvarez1 ponto
-
Na prática, o problema é bem mais amplo. Ao consultar os XMLs gerados pelo ACBrNFSeX no Recebedor Nacional, continuam surgindo caracteres inválidos, mesmo com a opção remover acentos habilitada. A transmissão utilizando codepage diferente de UTF-8 gera inconsistências no próprio provedor nacional, que passa a retornar a NFSe com erro. Como consequência, o XML da nota fiscal apresenta diversos problemas de acentuação, impedindo a importação correta pelos sistemas de contabilidade. No final, esses erros acabam sendo atribuídos aos sistemas emissores. É importante reforçar que esse comportamento está diretamente relacionado ao Delphi, que não utiliza string UTF-8 nativa, diferentemente do Lazarus, onde as strings já são UTF-8 por padrão. A falta de conversão explícita para UTF-8 no Delphi é a causa raiz do problema.1 ponto
-
Alberto, ja olhou o demo?1 ponto
-
Boa noite, No meu caso até não tenho problemas em remover a acentuação ao Gerar o DPS. Porém, ao capturar o XML para armazenar no database através da property ACBrNFSeX.NotasFiscais.Items[0].XmlNfse está com problemas nas acentuações como por exemplo na tag xTribNac. Obs.: O XML da NFSe salvo no diretório está com os caracteres corretos. Obrigado a todos pela colaboração.1 ponto
-
e no ambiente nacional?1 ponto
-
Agora é entender se ele está ok junto ao projeto nacional. mas lembro de ter visto para alguém e era só dados incorretos1 ponto
-
Pedido à comunidade Esse problema de acentuação / charset UTF-8 no NFSeX – Provedor Nacional já foi relatado diversas vezes e afeta principalmente ambientes Delphi 2009+. Peço, por gentileza, que os usuários que enfrentam o mesmo erro: Testem as alterações propostas Confirmem a correção do envio e do retorno da NFSe com acentuação UTF-8 correta Marquem aqui nos comentários caso também tenham esse problema A participação de vocês ajuda a demonstrar que o erro é recorrente e reforça a necessidade de commit da correção nos fontes, eliminando definitivamente paliativos como a opção de “remover acentos”. Obrigado a todos pela colaboração.1 ponto
-
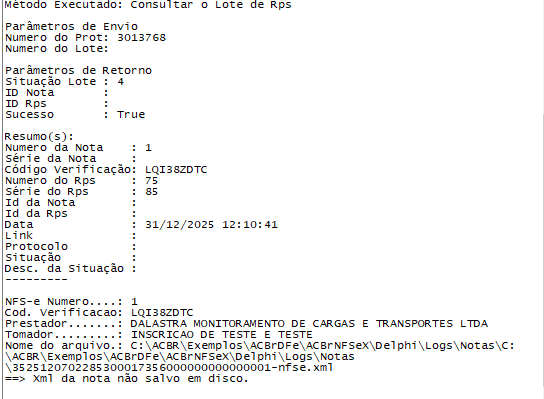
Ola pessoal, GovDigital emitindo normal agora na prefeitura de Lavras, diretamente no servidor próprio, notas com ou sem retenção de tributos.1 ponto
-
Boa tarde @Mychel Dambros, Já esta no SVN.1 ponto
-
Galera, depois de bater muito a cabeça consegui fazer funcionar. <IBSCBS> <CST>200</CST> <cClassTrib>200022</cClassTrib> <gIBSCBS> <vBC>41.70</vBC> <gIBSUF> <pIBSUF>0.0000</pIBSUF> <gRed> <pRedAliq>100.0000</pRedAliq> <pAliqEfet>0.0000</pAliqEfet> </gRed> <vIBSUF>0.00</vIBSUF> </gIBSUF> <gIBSMun> <pIBSMun>0.0000</pIBSMun> <gRed> <pRedAliq>100.0000</pRedAliq> <pAliqEfet>0.0000</pAliqEfet> </gRed> <vIBSMun>0.00</vIBSMun> </gIBSMun> <vIBS>0.00</vIBS> <gCBS> <pCBS>0.0000</pCBS> <gRed> <pRedAliq>100.0000</pRedAliq> <pAliqEfet>0.0000</pAliqEfet> </gRed> <vCBS>0.00</vCBS> </gCBS> <gTribRegular> <CSTReg>200</CSTReg> <cClassTribReg>200022</cClassTribReg> <pAliqEfetRegIBSUF>0.1000</pAliqEfetRegIBSUF> <vTribRegIBSUF>0.04</vTribRegIBSUF> <pAliqEfetRegIBSMun>0.0000</pAliqEfetRegIBSMun> <vTribRegIBSMun>0.00</vTribRegIBSMun> <pAliqEfetRegCBS>0.9000</pAliqEfetRegCBS> <vTribRegCBS>0.38</vTribRegCBS> </gTribRegular> </gIBSCBS> </IBSCBS> Obrigado a ajuda de todos.1 ponto
-
Consegui aqui... 75-env-lot.xml tem que mandar assim: <ItemListaServico>11.04</ItemListaServico> <CodigoTributacaoMunicipio>11.04</CodigoTributacaoMunicipio> tive que mudar outras informaçoes de pis cofins e ISS.. veja o XML anexado caso queira...
1 ponto
-
Boa tarde Tentei implementar uma quebra de linha no campo InfAdic.infCpl com ';' , mas não obtive o resultado esperado , eu desejava pular mais que uma linha deixando uma linha em branco para a questão de um layout com melhor visualização mas não tinha sucesso informando duas vezes = ';;' . Informando ';' ou ';;;;;;' na frente das Strings enviada ele quebra apenas uma única linha , percebi que existe uma função QuebraLinhas(...) que é a causa do problema , no caso implementei o ';' na chamada e resolveu . Se puderem avaliarem por gentileza . Para facilitar é na linha 502 da unit em anexo . Obrigado . ACBrSATExtratoESCPOS.pas1 ponto
-
Boa tarde. Eu seto a propriedade LerNossoNumeroCompleto como True, para todos os bancos. Do Bradesco tem que setar para False. Para contornar isso, ja que só se sabe o banco apos ler o arquivo, criei uma função para abrir o arquivo, verificar se é Bradesco. Boleto.LerNossoNumeroCompleto := NumeroBancoCompleto; function NumeroBancoCompleto: boolean; var iArq: TStringList; iCnab400: boolean; iColuna: integer; begin iArq := TStringList.Create; with iArq do begin try LoadFromFile(Boleto.NomeArqRetorno); iCnab400 := Length(Strings[0]) > 240; iColuna := iif(iCnab400,77,1); Result := not (Pos('237;',Copy(Strings[0],iColuna,3)+';') <> 0); finally Free; end; end; end;1 ponto
-
Resposta da RECEITA FEDERAL Prezado cidadão, Em atenção à sua manifestação, sugere-se que o interessado entre em contato diretamente com o Município competente, a fim de obter os esclarecimentos e providências cabíveis sobre o assunto. Sempre que precisar, conte com a Ouvidoria para registrar denúncias, reclamações, sugestões ou elogios sobre os serviços da Receita Federal do Brasil. Nosso papel é garantir que você exerça seu direito de se manifestar. A Ouvidoria agradece o seu contato.0 pontos